Discover what the highest rated Respiratory CRO has to offer.
Sep 4, 2025 11:00 AM EDT
Discover what the highest rated Respiratory CRO has to offer.

Discover what the highest rated Dermatology CRO has to offer.
Sep 4, 2025 11:00 AM EDT
Discover what the highest rated Dermatology CRO has to offer.
Discover what the highest rated Psychiatry CRO has to offer.
Sep 4, 2025 11:00 AM EDT
Discover what the highest rated Psychiatry CRO has to offer.
Discover what the highest rated Women's Health CRO has to offer.
Sep 4, 2025 11:00 AM EDT
Discover what the highest rated Women's Health CRO has to offer.
Discover what the highest rated Medical Device CRO has to offer.
Sep 4, 2025 11:00 AM EDT
Discover what the highest rated Medical Device CRO has to offer.
Discover what the highest rated Digital Therapeutics CRO has to offer.
Sep 4, 2025 11:00 AM EDT
Discover what the highest rated Digital Therapeutics CRO has to offer.


Dr. Billings brings over 40 years of experience spanning academia, government, and industry. He has deep expertise in the diagnostics sector, having previously served as Chairman and CEO of Biological Dynamics, a molecular diagnostics company, and as Chief Medical Officer of Natera, a leading genetic testing company focused on oncology, women’s health, and organ health.

Rob is a Director of Strategic Solutions at Lindus Health, overseeing the design and execution of large-scale clinical trials with a focus on diagnostics and screening studies. He has extensive experience in healthcare product development and clinical trial strategy. With a background in behavioral and clinical science, Rob specializes in translating complex operational challenges into scalable, innovative trial designs.
Large-scale oncology screening trials require not only enrolling tens of thousands of participants but also keeping them engaged and capturing complete clinical data over years of follow-up. On average, 25-26% of clinical trial participants drop out after expressing consent, and over 90% of studies experience delays linked to retention challenges. In a screening study where cancer events occur in only a small fraction of the population, missing even a handful of cases can compromise endpoint validity.
"Every cancer case in a large screening trial must be fully documented, with complete diagnostic, staging, treatment, and outcome data. Losing even a small number of cases to incomplete follow-up can undermine the statistical power the entire study was designed to achieve. The operational model has to be built around preventing that from the start." - Dr. Paul Billings
The solution requires three interconnected systems working together:
All three systems are enabled by the same decentralized or hybrid trial design described in Part 1: neither the participant nor their data is tethered to a physical site, which means follow-up continues regardless of where a participant lives, moves, or receives care.
The majority of participants in a screening trial remain asymptomatic and healthy throughout the study. They may have no symptoms driving them back to a clinic, no personal health motivation to stay engaged, and minimal touchpoints with the study team. Over multiple years, people can naturally disengage, change their contact information, or simply forget they enrolled.
Sustaining engagement with this population starts with reducing the burden of participation. The same decentralized infrastructure described in Part 1 (home phlebotomy, local lab networks, flexible self-scheduling) removes friction that would otherwise drive attrition during follow-up: no travel to distant sites, no repeated coordination with research staff, no passwords or app downloads to remember. Because the study design isn't completely tied to a physical site, participants who relocate can continue remotely wherever they are. But low-burden logistics alone aren't enough to keep asymptomatic volunteers engaged over multiple years. The study needs an active engagement layer built on top of that foundation.
That engagement layer starts with brief, periodic health status surveys (e.g., quarterly or semi-annual) that participants complete on their own devices. These surveys serve a dual purpose: they maintain a regular touchpoint between the participant and the study, and they surface health status changes (new diagnoses, treatments, hospitalizations) that trigger targeted downstream data collection. The survey experience has to minimize friction - deployment as a simple web link with no app downloads, no login credentials, and no portal to navigate is an effective way to achieve this. Personalized, automated reminders via email and SMS, configurable at the individual participant level so timing fits each person's routine, keep response rates high without requiring manual outreach for the vast majority of participants. Citrus™, Lindus' eClinical platform, is purpose-built for sustained, low-friction participant engagement across large populations.
The content of those communications matters as much as the timing. Pre-appointment reminders with clear instructions, thank you messages after completing activities, and progress updates highlighting each participant's contribution to cancer research all help sustain the sense of purpose that keeps asymptomatic volunteers engaged over years, not just months.
Behind this participant-facing layer sits a structured escalation system designed to catch disengagement early. Dedicated virtual patient coordinators provide proactive outreach to participants who show signs of disengagement, with automatic escalation workflows that flag at-risk individuals before they're lost to follow-up. When a participant misses an ePRO or scheduled activity, the system initiates automated reminders within specified days of the due date. If the participant still hasn't responded, the platform flags the overdue activity to the trial coordinator, who begins direct outreach via phone and email. If multiple contact attempts over several days don't re-engage the participant, the case is escalated to the broader study team and sponsor for review. Every contact attempt is documented, creating a complete audit trail that demonstrates the study made every reasonable effort to retain each participant. Figure 1 illustrates this escalation framework.
%20.png)
In a screening trial at this scale, cancer diagnoses, treatments, and outcomes will be documented at thousands of different healthcare facilities. Participants receive care from their own providers, not from the study site. The record retrieval infrastructure has to reach all of them.
This begins at enrollment, where participants complete a single HIPAA authorization during the consent process that covers retrieval from any US facilities the patient may use for the duration of the study. There are no per-provider authorization forms required in the majority of cases; however, a small proportion of facilities may require a provider-specific authorization. One signature at enrollment covers the life of follow-up for the vast majority of record pulls, with a pre-built process for handling additional authorizations where needed.
A nationwide retrieval partner with an embedded footprint across major US health systems provides direct access to records, with field teams extending coverage to rural and out-of-network facilities. Multiple follow-up attempts per request are built into the process to maximize completeness.
The output is searchable, OCR-processed PDF medical records covering encounters, procedures, labs, imaging reports, pathology, diagnoses, and treatments. These records feed directly into the AI-assisted abstraction and clinical data review workflows described below, where study-specific fields are extracted, mapped to CRF definitions, and loaded into the EDC. Figure 2 outlines this end-to-end workflow.
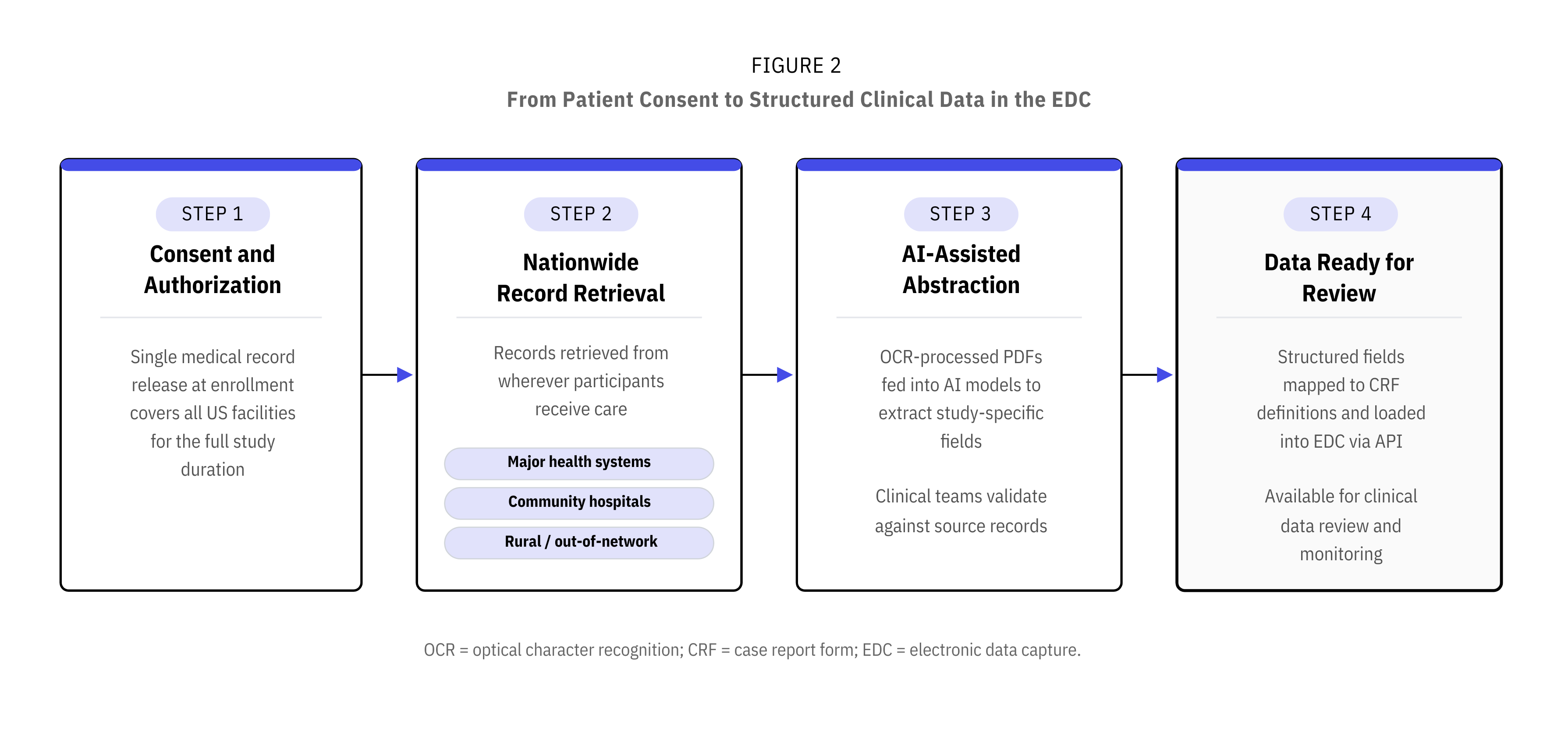
In a long-term follow-up study, medical record retrieval is a recurring operation. Records generally need to be checked at regular time points over years across the full study population. Pulling records for all participants at every interval would be prohibitively expensive when the vast majority remain cancer-free.
A layered triage approach solves this. The ePRO health status survey serves as the primary detection layer across the entire study population. Cross-referencing against an identifiable claims database provides a supplementary check that catches oncology-related health events participants may not self-report, such as incidental findings or care received outside their usual provider. Full medical record pulls can be triggered for participants where either the ePRO or the claims data indicates a relevant health event. Participants who report no changes and have no oncology claims can have their record pull skipped for that period. Figure 3 demonstrates this decision framework.
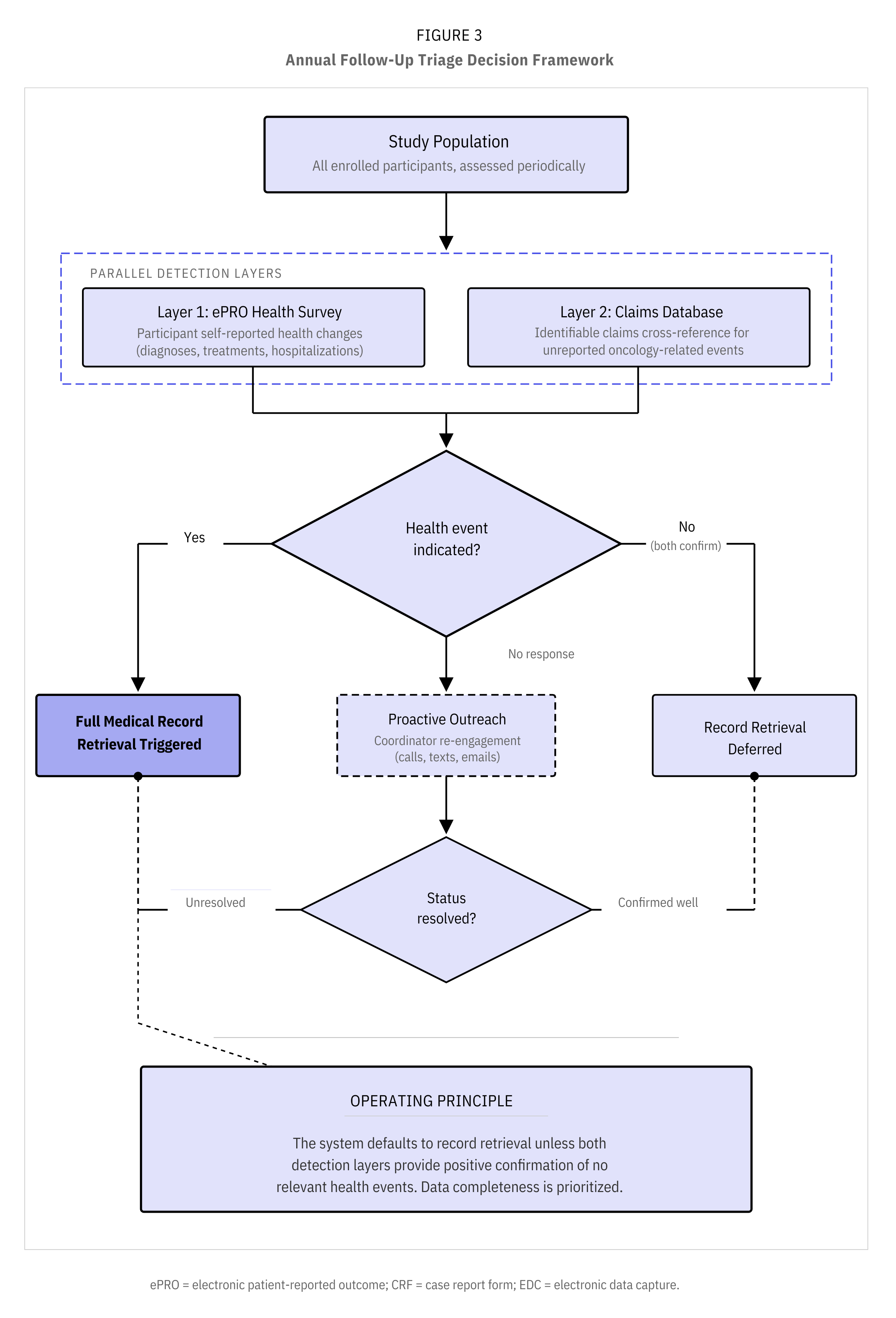
To put this in perspective: in a 25,000-participant study where an estimated 2-3% may develop cancer annually, the triage approach concentrates record pulls on the subset with confirmed or suspected health events rather than pulling for all 25,000 each year. The specific criteria that trigger a pull are aligned between the sponsor, the CRO, and the retrieval partner, ensuring the triage logic matches the study's endpoint definitions. Those savings compound with each year of follow-up, all while maintaining complete data capture for every clinically meaningful event.
Keeping Asymptomatic Participants Engaged for Years
With tens of thousands of participants, even a modest annual non-response rate to ePRO surveys means thousands of people requiring follow-up outreach each cycle. If that outreach depends on manual effort, the coordinator team has to grow every year as the cumulative number of non-responders grows. The automation layer carries the majority of the workload: configurable reminder schedules, multi-channel outreach (email, SMS), and escalation workflows that automatically flag non-responders for human follow-up. Virtual patient coordinators then focus their time on the subset of participants who need direct outreach to complete study activities, rather than managing reminders for the entire population.
Maintaining Data Quality Across Repeated Annual Record Pulls
Quality validation is manageable when medical records are only retrieved once, but when the same process runs annually for years across the entire cohort, errors compound and edge cases multiply. A 2025 multicenter study across 10 institutions found that AI extraction from unstructured medical records had a lower error rate than manual abstraction (7% vs 14%), and that a hybrid AI-human workflow further reduced errors to 4.4%. The same principle applies here: AI models extract structured data at each timepoint, clinical data teams compare abstracted output against source PDFs, and edge cases are fed back into the models to improve accuracy over time. Source PDFs are retained alongside abstracted data for audit trail and source data verification. For the most critical fields, human abstractors can manually key data as a high-control fallback. We've built API integrations between retrieval partners and the EDC on another large diagnostic trial, mapping abstraction fields directly to CRFs and eliminating manual data entry.
Participants Who Don't Respond to Either Detection Layer
The triage system works when participants complete their ePRO or appear in the claims database. Over five years at this volume, some will do neither, and the system needs to account for this. Non-responders receive proactive outreach from virtual patient coordinators (calls, texts, emails) to re-engage them and collect their health status. If a participant's status remains unknown after outreach, they are treated as requiring a record pull rather than skipped. The triage logic only skips a pull when there is positive confirmation of no relevant health events from the ePRO, the claims database, or both. This means the system defaults to over-pulling rather than risking a missed cancer case, which is the right trade-off for a study where every event matters for endpoint validity.
The infrastructure described in Part 1 for enrollment, identity verification, sample collection, and data capture provides the foundation. Long-term follow-up adds a layer of sustained engagement and repeated data collection, requiring its own operational systems. The ePRO engagement layer, the triage logic for targeted record pulls, and the retention workflows are purpose-built for this phase of the study and are architected to scale to the volumes required by next-generation MCED studies.
In prior studies with extended follow-up periods, we've achieved retention rates as high as 90% over 12 months in a rare disease population (a Myasthenia Gravis symptom-tracker study), where retention was a known challenge, an approach recognized by Fierce Biotech in the Fierce CRO awards, where we won the Outstanding Patient Recruitment and Retention category. Our partnership with a nationwide medical record retrieval network provides broad access to US electronic medical records, with validated API integrations that map abstraction fields directly to CRFs. These capabilities are in active use across our current portfolio of large-scale diagnostic trials.
If you're running or planning a large-scale screening trial and need confidence that your long-term follow-up data will be complete when it matters most, Lindus can help you design the operational model and deploy the systems to make it happen.
This is Part 2 of a three-part series on operational strategies for large-scale liquid biopsy screening trials. In Part 3, we'll address how to ensure FDA-grade evidence quality when collecting data through virtual and hybrid pathways.

